Silent Tags: Distilling Explicit Paralinguistic Control into Hidden Space for Omni Speech
We introduce Silent Tags, a Thinker-frozen framework for expressive speech-to-speech models. Only the Talker is trained — cross-attention to the Thinker's lower hidden states provides implicit paralinguistic control with no extra tokens and no reasoning cost. On ParaS2SBench and EmergentTTS-Eval, Silent Tags matches or surpasses explicit-tag baselines while fully preserving MMLU and VoiceBench scores.
Same Thinker; vanilla Talker vs. Silent Tags. All inputs are spoken queries — responses are generated end-to-end with no explicit tags at inference.
| User Query | Emotion | Response | Prosody | Baseline(Qwen2.5-Omni) | Silent Tags |
|---|---|---|---|---|---|
| I finally finished my dissertation after three years! | Joyful | Three years of hard work — and now it's done. That's a huge achievement. | cheerful / excited | ||
| Why did you do that? I told you not to touch my things. | Angry | I'm sorry — I didn't mean to upset you. Can we talk about it? | gentle / apologetic | ||
| I'm feeling really tired lately and I don't know why. | Sad | That kind of persistent tiredness can be really draining. Sometimes our body is asking us to slow down. | soft / empathetic | ||
| [Whispered] I'm in a library — can you keep it down? | Neutral | Of course, I'll keep my voice low. What can I help you with? | whisper | ||
| I just lost my job, but I have an interview tomorrow. | Anxious | That sounds really tough. But having an interview lined up already — that's something to hold on to. | soothing→encouraging |
Silent tags re-read the Thinker's hidden states at every decoding step, so a reply can open soothingly and pivot to an encouraging tone mid-sentence — no inline tags inserted.
| Scenario | Response (prosody labels shown for reference only) | Baseline(Qwen2.5-Omni) | Silent Tags |
|---|---|---|---|
| User distressed about a setback | soothing "I hear you — that's genuinely hard, and it's okay to feel overwhelmed." → encouraging "But you've navigated tough situations before, and you have more tools than you realise." | ||
| User shares exciting news nervously | warm "That's wonderful news — congratulations!" → excited "I can only imagine how much work went into this. You should be really proud!" | ||
| Sarcastic question about obvious advice | dry "Yes, drinking water when you're thirsty is indeed recommended." → playful "But in all seriousness, hydration has measurable effects on focus — want the details?" |
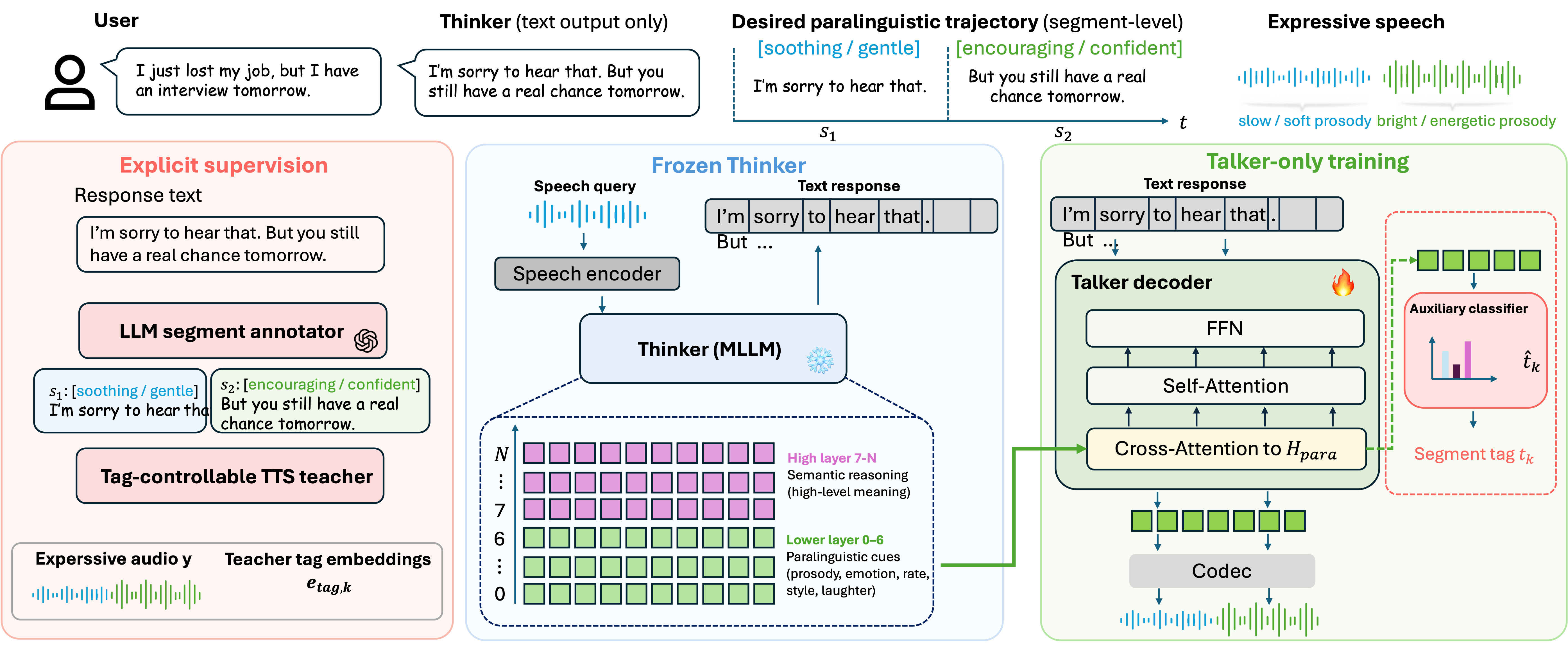
Silent Tags comprises three components: a paralinguistically-annotated S2S corpus, a Talker extended with cross-attention over the Thinker's lower hidden states, and a Talker-only training objective. The Thinker is always frozen.
A GPT-4-class LLM annotates responses with per-segment paralinguistic tags (48 categories covering emotions, speaking styles, and vocal events). A tag-controllable TTS teacher renders each segment and provides dense tag embeddings. The Talker's cross-attention reads only layers 0–6 of the Thinker — where paralinguistic content concentrates — forming silent tags: dense, step-by-step prosodic representations.
Training loss: L = Lgen + λ₁ Ldistill + λ₂ Laux. The distillation loss aligns silent tags with teacher embeddings; the auxiliary classifier predicts segment-level tags. Both are discarded at inference — no tokens, no extra latency.
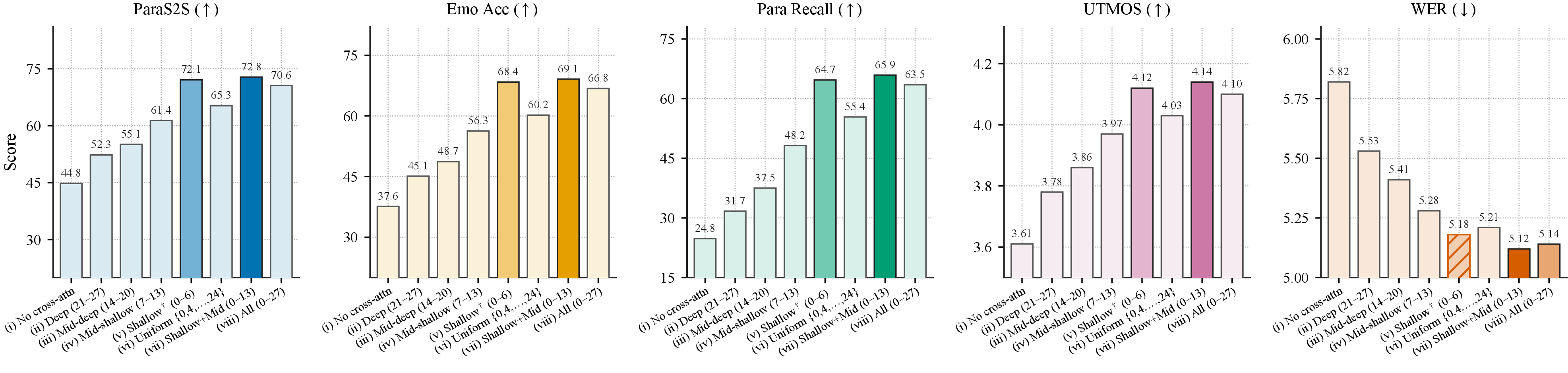
Layer selection. Layer-wise studies on text and speech Transformers consistently report that lower layers preferentially encode prosodic, affective, and speaker information, while upper layers carry semantic content. We confirm this for an omni-modal Thinker before designing the Talker. Specifically, we train per-layer linear probes on frozen Qwen2.5-Omni hidden states to predict three paralinguistic events from a held-out subset of our corpus and report the F1 score at each layer (Figure 2). The probe accuracy peaks sharply around layer 4 (averaged F1 of 78.7%, surpassing a Whisper-Large-v3 reference at 73.4%) and degrades monotonically toward the upper layers, falling below the random and text-embedding baselines beyond layer 20. This empirical layer profile motivates a hard cut: we designate layers 0 to 6 as paralinguistic layers and layers 7 to L as semantic layers, and restrict the Talker's cross-attention to the former, so that the semantic generation pathway is left intact while the paralinguistic readout is concentrated where the signal is strongest.
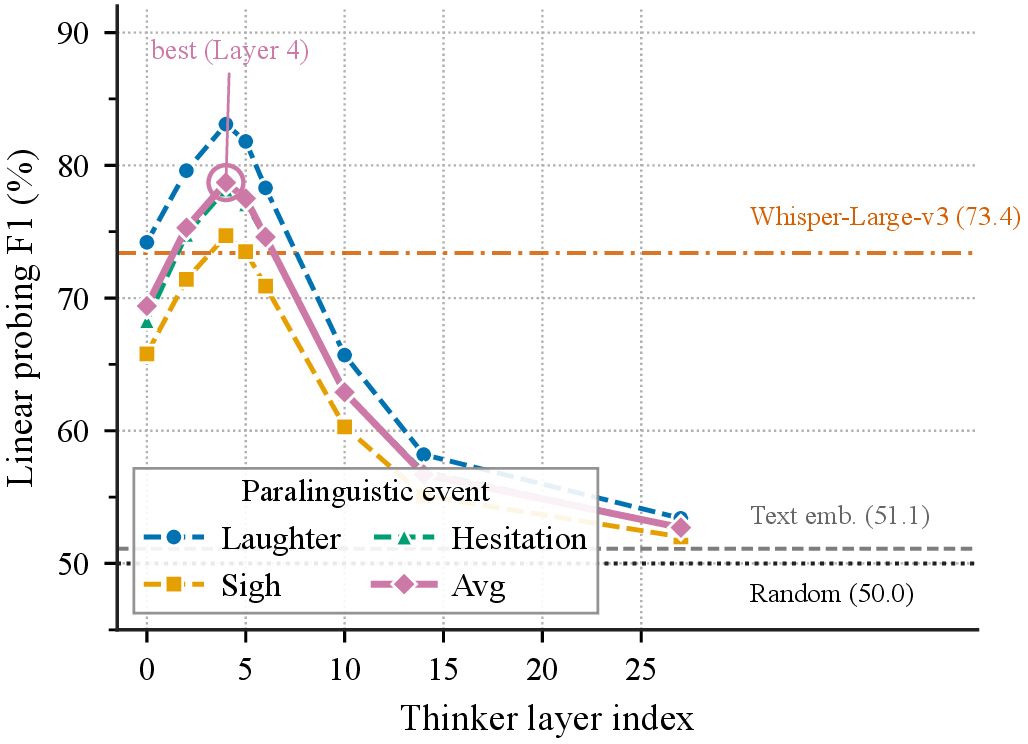
Silent Tags reaches 4.31 average score on ParaS2SBench (Qwen3) and 65.7% win rate on EmergentTTS-Eval (Kimi-Audio), matching or surpassing explicit-paradigm methods that modify the Thinker.
Crucially, VoiceBench (72.2 vs 72.4), MMLU (68.0 vs 68.1), and GSM8K (64.6 vs 64.7) are fully preserved — explicit methods lose 2–5 MMLU points and 4–7 GSM8K points.